
Image Matching Now Supporting iBeacon Results
Every second counts when the ASK team is responding to visitor questions. With that in mind, a few weeks ago we looked into how we could use image matching to match visitor photos to objects and make it even easier for the ASK team to find the object a visitor is asking about. This idea came to us after working with the students at Cornell Tech. The Cornell team was using image matching slightly differently in their own project, but it sparked an idea in our own team and we started to experiment to to see if we could use it to help improve efficiency of the ASK team.
There is a lot of research into Computer Vision right now but most of it focuses on image recognition (identifying a thing in an image like a dog, car, tree, etc.) but for this project we need to do image matching which is comparing the entirety of an image to see if it is the same or similar to another image. The most common use of image matching is a reverse image search. Google has a service like this where you can give it an image and it will search the web to see if the same photo is out there on the web somewhere even if it has been slightly cropped or edited. For example, I did a reverse image search to see if one of my photos is used anywhere else and found a tumblr blog and a few sites in Japan that are using it.

Original image on the left. Modified version found through a reverse image search on the right.
What we’re doing is quite different than just trying to find the same photo. We want to see if part of a photo matches the official image of an object in the museum collection. After some searching, we found an open source tool called Pastec. (Special thanks to John Resig for bringing Pastec to our attention.) From it’s GitHub repo homepage, “Pastec does not store the pixels of the images in its database. It stores a signature of each image thanks to the technique of visual words.” Because it uses parts of the image to make “visual words” and we are trying to match an object that would be in a photo, not the photo itself, it seemed like a promising option. (The visual words concept is very interesting and if you’d like to read more about it, check out this Wikipedia page.)

Visitor image on the left. Brooklyn Museum original image on the right.
To test out Pastec, we compared visitor images to the official image on a few objects in the collection. It matched flat 2D objects, like paintings and photographs, about 92% of the time but only matched 3D objects, like sculptures, about 2% of the time. This makes sense since recognizing 3D objects is a whole separate and even harder problem which Pastec isn’t designed to do. Again from the GitHub homepage, “It can recognize flat objects such as covers, packaged goods or artworks. It has, however, not been designed to recognize faces, 3D objects, barcodes, or QR codes.” Still, recognizing a huge portion of the collection 92% of the time would be very useful so we decided to move forward.
The next step was to upload the main image for every object in the collection through Pastec so it can index it and find the visual words. The indexing took about 36 hours on an m1.medium AWS EC2 instance which has two ECUs (EC2 Compute Unit) with 3.75 GB of ram. One ECU is roughly equivalent to a 1.0-1.2 GHz Opteron processor. After indexing all objects in the collection we tested searching for an image match and were getting results back in under 1 second. We also tested search speed with only 2D objects in the index, since they were so much more likely to match than 3D objects, but the difference in search speed was so minimal we decided to index them all. With that information we were ready to implement image search results into the dashboard.
When chatting with visitors, the ASK app uses iBeacon data to show the team a thumbnail grid of what objects are near a visitors current location. This location data is the main research tool for ASK team because it helps them see the object’s data, past conversations about the objects, and objects nearby the visitor. Image matching is a supplement to it and the design should reflect that. So in the dashboard if there is a match, that object will be highlighted above the main grid of images, and if there isn’t a match, nothing extra will show.
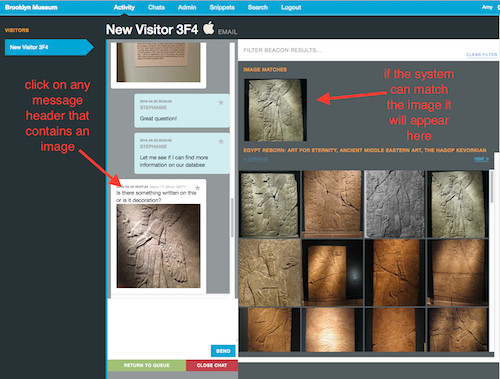
If we can match an image, we display it above the other images, so the ASK team has quick and easy access without having to hunt for it.
In the end, the experiment of “Can we use image matching to supplement iBeacon data?” was well worth the effort because after about a week’s worth of work we’re able to shave a few seconds off of the time it takes to get back to visitor questions making that experience more seamless. There is a secondary benefit as well because now that the image index is created it has potential to help solve more problems down the road and could be a great research tool.


Kim - 8 years ago
Love it, what a fabulous way to stretch the technology –